Сегодня я расскажу про контекст-инжиниринг: как правильно управлять памятью и вниманием LLM-моделей при разработке проектов и AI-агентов. Вы узнаете, почему загружать всю доступную документацию в промпт — плохая идея, как структурировать данные по слоям и как правильно передавать контекст между сессиями. Этот материал поможет получать от нейросетей точные, предсказуемые результаты без галлюцинаций и переплат за токены.
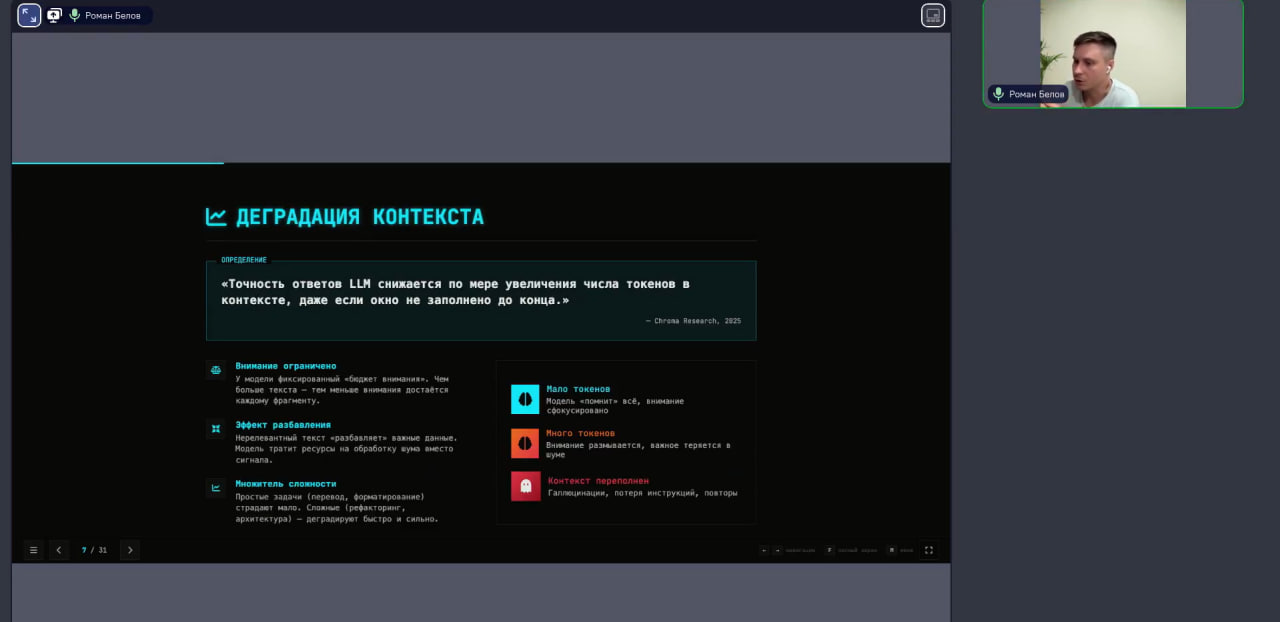
00:03–02:02 Введение в контекст-инжиниринг — суть управления контекстом и план вебинара. 02:04–06:28 Угрозы большого контекста — почему заявленные 200 000 токенов являются маркетинговой иллюзией и как перегрузка оперативной памяти агента приводит к галлюцинациям. 06:28–10:44 Деградация контекста и эффект разбавления — почему проседает эффективность в середине контекстного окна и как шум влияет на принятие решений. 10:45–19:25 Шесть слоев контекста — разделение информации на системные инструкции (claude.md), стэк проекта, задачи, внешнюю документацию, критерии готовности и примеры. 19:26–24:50 Обязательный и вредный контекст — почему нельзя отдавать всю кодовую базу (legacy) разом и зачем жестко прописывать архитектурные ограничения. 24:50–32:32 Персистентность памяти между сессиями — стратегии сохранения прогресса через текстовые файлы, версионирование…
🔒
Этот материал доступен участникам Клуба. Войдите или оформите доступ,
чтобы читать целиком, открывать видео и комментировать.