В этом уроке я разбираю методику создания личной базы знаний, вдохновленную подходом исследователя ИИ Андрея Карпаты (LLM Wiki). Ключевой посыл: использование связки Obsidian и Claude позволяет превратить массив неструктурированных данных (транскрипты, статьи, подкасты) в системную базу концепций и протоколов, адаптированную под ваши личные цели. Вебинар будет полезен всем, кто работает с большими объемами информации, проводит глубокие исследования или хочет системно изучить сложную тему (на примере здоровья, долголетия или подготовки к марафону).
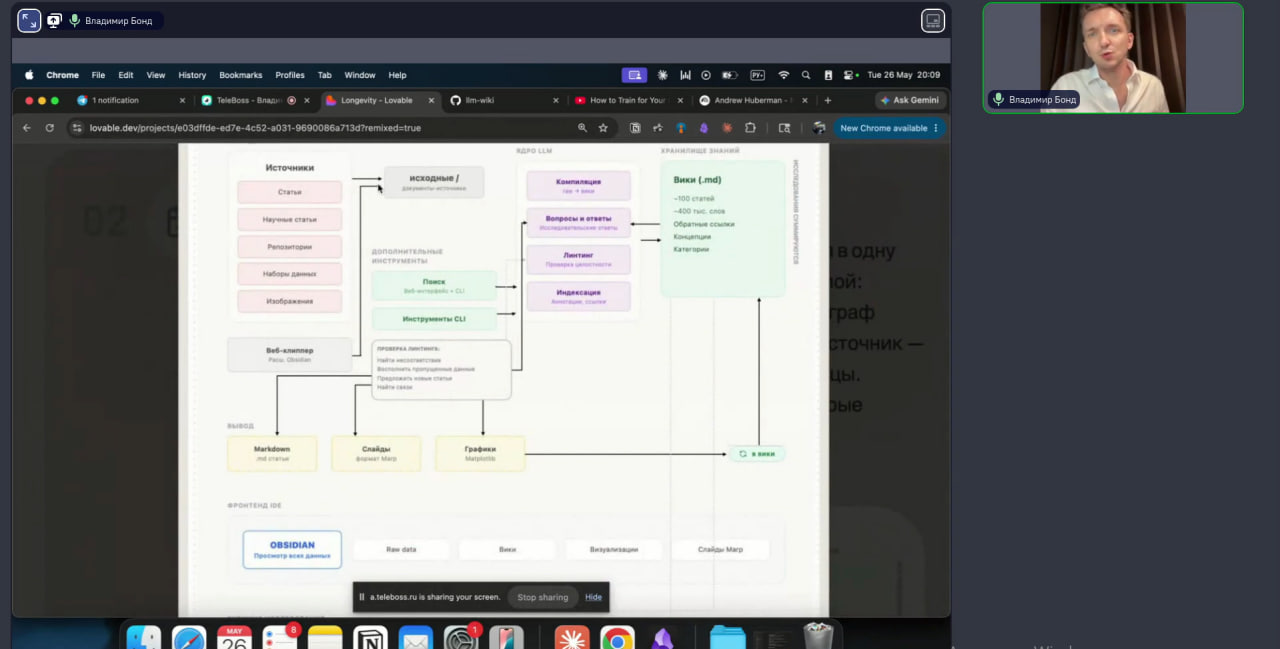
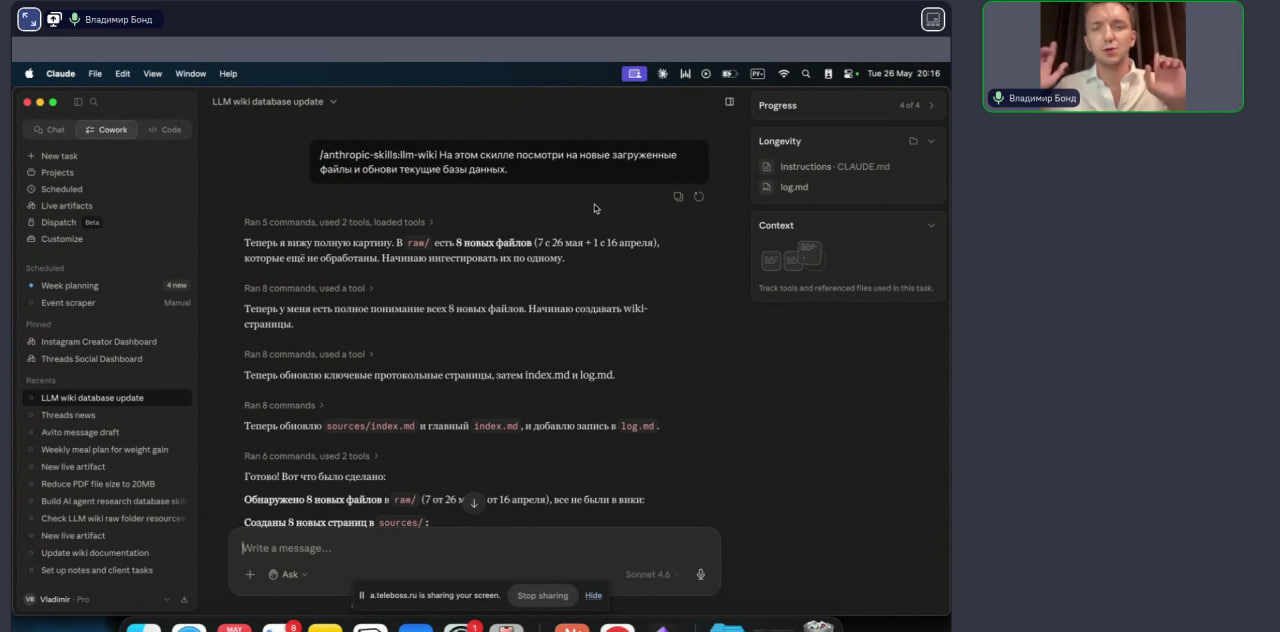
00:13–02:25 Введение в метод Карпаты по работе со знаниями и выбор темы longevity для тестирования. 02:43–04:37 Трехслойная архитектура базы: сырые данные, слой вики и слой сгенерированных артефактов. 04:38–06:47 Демонстрация базы данных в Obsidian и работы визуального графа связей. 06:47–10:30 Создание системного промпта (скилла) в Claude на основе GitHub-репозитория и адаптация формата концепций под себя. 10:31–12:38 Сбор данных: как загружать длинные транскрипты с YouTube через WebClipper в папку сырых источников. 12:40–14:34 Автоматическое создание саммари, выделение сущностей и протоколов при загрузке новых видео. …
🔒
Этот материал доступен участникам Клуба. Войдите или оформите доступ,
чтобы читать целиком, открывать видео и комментировать.