
Человек отменил репетитора по французскому за $200 в месяц. Вместо него собрал на Claude замену за пару долларов — и она помнит его ошибки лучше живого учителя. И таких историй «собери сам и сэкономь» сегодня много. Крошечную модель на 0.6B бесплатно дообучили дома до 92% точности. Скиллы перестают быть пустышкой. А оркестр моделей Sakana обходит одиночные топ-модели. И ещё: Anthropic теперь просит показать паспорт — разбираемся, кого это касается.
Главное за 30 секунд
- Anthropic вводит проверку личности по паспорту и селфи для отдельных случаев — и это повод задуматься о приватности.
- Sakana Fugu прячет за одним API оркестр моделей и на тестах догоняет Fable 5 и Opus 4.8.
- HyperFrames делает рекламное видео-промо из ссылки на сайт прямо в Claude Code, бесплатно.
- Крошечную модель на 0.6B дообучили дома до 92% точности без единого платного токена.
- Скилл полезен, только если хранит то, чего свежая модель ещё не знает; иначе это пустышка.
Внедряем и улучшаем
Видео-лендинг из одной ссылки: скилл HyperFrames. Команда HeyGen выложила бесплатный открытый скилл, который превращает сайт в рекламный ролик прямо в Claude Code или Codex. Раньше за такое студии брали тысячи долларов. Ставим одной строкой в терминале:
npx skills add heygen-com/hyperframes
Самый быстрый путь — навык /website-to-video. Он сам вытащит с сайта скриншоты, тексты, ассеты и фирменный стиль, и соберёт промо за один проход:
Use /website-to-video to turn [вставь URL] into a 30s promo video.
Для ролика покрасивее у автора есть пятишаговый рецепт. Соберите ассеты и опишите их в frame.md, распишите сцены в storyboard.md, подтяните готовые анимации из репозитория. Затем проверьте статичные кадры — по одному HTML-макету на сцену. И только потом рендерьте и доводите в редакторе Studio. (HyperFrames на GitHub, разбор Питера Янга)

Пусть ИИ сам ставит себе цель и проверяет работу. Приём от Мэтта Бермана, который разобрал The Neuron: вместо точных шагов давайте модели цель и петлю «сделай — оцени себя — найди главный пробел — продолжай». Модель сама пишет критерии «достаточно хорошо» и сверяется с ними, пока не дойдёт. Берман гоняет так Codex: «ускоряй дашборд, пока страница не загрузится максимально быстро, не меняя того, что видит пользователь». Готовый промпт под /goal целиком:
/goal
Work toward this outcome:
[опиши задачу]
Before starting, define what "good enough" means for this task.
Create 3-5 success criteria Codex can keep checking while it works. Include any hard requirements, tests, files, constraints, style rules, performance targets, or user-facing behavior that must be preserved.
Then work in a loop:
1. Make the next useful improvement.
2. Judge the result against the success criteria.
3. Identify the biggest remaining gap.
4. Continue until the work meets the goal.
Return:
- The final result
- The success criteria you used
- The biggest change you made.
Что это значит: для размытых задач без чёткого теста модель-судья тянет результат к цели лучше, чем длинный список шагов. (The Neuron)
Скиллы, которые реально работают, а не пустышки. Энсон Биггз разобрал свежее исследование SkillsBench и согласился с выводом: скилл, который модель пишет сама с нуля, бесполезен. Логика простая. Если модель не смогла решить задачу, а вы просите её «написать гайд по задаче», она просто пересказывает то, что и так знает — это «блок размышлений, только хуже». Скилл ценен, лишь когда хранит знание, которого у свежей модели нет.
Откуда такое знание берётся — три рабочих случая. Первый: контекст проекта, который базовая модель знать не может (как запускать тесты, где лежит CI, нестыковка x86 и Mac). Второй: то, что вы часто повторяете руками. Третий и главный — знание, добытое в муках. Биггз советует: «Почти каждый раз, когда мне пришлось вмешаться в задачу, я после того, как агент выпутался, спрашиваю — какого знания ему не хватило, чтобы решить самому». И вот этот ответ уже превращаю в скилл. Сам скилл — это просто папка: SKILL.md с метаданными, рядом готовый скрипт-команда, чтобы агент не переписывал её каждый раз, и подпапка references/ для краевых случаев. Держите его узким: исследование показало, что 2–3 коротких модуля бьют большую документацию. (Anson's Notes)
Дообучить крошечную модель дома до 92% — без единого платного токена. Торгейр Хельгеволд показал полный рецепт: как 600-миллионную Qwen 3:0.6B превратить в надёжный классификатор вопросов для своего домашнего ИИ-помощника. Сырая модель с честным промптом дала всего ~10% точности: путала категории и выдумывала несуществующие. После дообучения через Unsloth по методу QLoRA на ~850 примерах — сразу ~79%.
Но главный трюк не в обучении, а в форме ответа. Модель путала «водяные» категории: бассейн, бойлер, фонтан. Автор заменил слова-метки на бессмысленные двухбуквенные коды (OO = бассейн, QQ = бойлер) и попросил выдавать код. Точность подскочила до ~92%. Код не несёт смысла — и модели нечего путать. Второй совет автора: не крутите гиперпараметры, дефолты Unsloth хороши, вкладывайтесь в качество датасета. И всегда держите отдельный тестовый набор, иначе не заметите переобучения. (teachmecoolstuff, код)
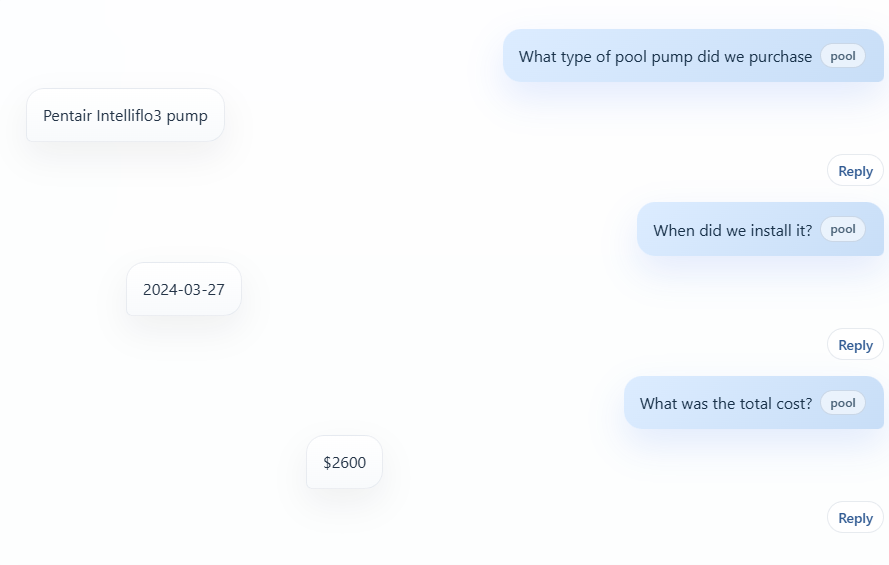
Собери себе ИИ-репетитора по любому предмету. Алекс Шелаев отменил репетитора по французскому за $200 в месяц и собрал замену на Claude за пару долларов. Архитектура переносится на любой предмет, так что разберём детально.
Две части, общая память. Первая — текстовый репетитор как проект Claude поверх одного JSON-файла. В файле каждая тема: когда повторяли, уверенность, что именно пошло не так, когда показать снова. Расписание держит алгоритм SM-2 — тот же, что в Anki: вы оцениваете припоминание от 1 до 4, и тема возвращается то через три недели, то завтра. Ключевая фишка — гранулярный учёт ошибок. Не «путает passé composé», а «берёт неверный вспомогательный глагол с глаголами движения в отрицании — с 12.04.2026». Следующее упражнение строится ровно вокруг этой поломки.
Вторая часть — голосовое приложение Causons для разговорной практики. Оно читает тот же JSON и ведёт беседу к слабым местам, поправляя только объективные ошибки. Важный принцип автора: «ложная правка хуже пропущенной». Под капотом — дешёвый стек из трёх вызовов: распознавание речи через Groq Whisper, чат на gpt-4o-mini, озвучка через OpenAI TTS. Около $0.04 за 15-минутную сессию. И отдельный урок по промптам: автор развёл стабильную «политику обучения» и текучий контекст дня по разным хранилищам — иначе старые списки тем молча перетирали настройки. (alshe.substack, код)
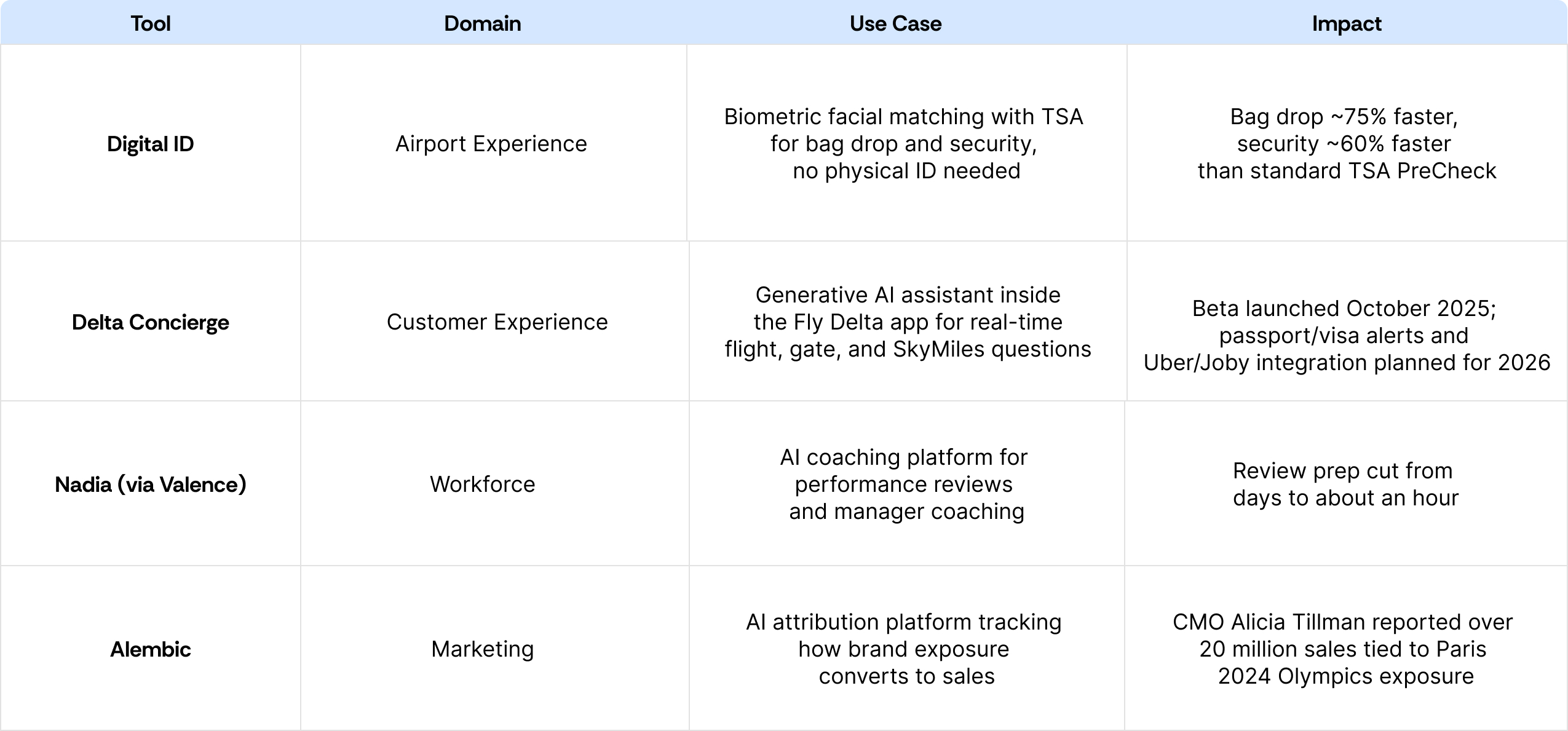
Как Delta встроила ИИ — и три урока для любого бизнеса. NeatPrompts разобрал, как одна из крупнейших авиакомпаний мира тащит ИИ в работу. APEX собирает данные с почти 900 самолётов и предсказывает поломки. Точность спроса на запчасти выросла с 60% до 90%, а капремонт двигателя ускорился со 150–200 дней до менее 90. Динамическое ценообразование от Fetcherr расширяют с 1% до 20% сети. ИИ для багажа в Атланте пересчитывает маршруты каждые две минуты и поднял успешные пересадки чемоданов на 20%.
Но ценность не в конкретных инструментах, а в трёх уроках. Первый: сначала фундамент, потом фича — Delta годами чистила данные и переносила 1300 приложений в облако, прежде чем подключать ИИ. Второй: медленный запуск — это фича, а не баг; «не будем спешить» спасло ценообразование от провального старта. Третий: дайте одной программе доказать модель, прежде чем масштабировать — логику APEX потом перенесли и на багаж, и на цены. (NeatPrompts)
Инструменты и штуки
Sakana Fugu. Многоагентная система, упакованная в один OpenAI-совместимый API: «одна модель, чтобы командовать всеми». Fugu сам подбирает и оркеструет пул сильных моделей под задачу — вы просто шлёте запрос на один адрес. Две версии: обычная Fugu (быстро, можно исключать отдельных провайдеров из пула) и Fugu Ultra (глубже пул, выше качество, дольше ответ). На бенчмарках держится вровень с Fable 5 и Mythos Preview. Fugu Ultra обходит Opus 4.8 на SWE-Bench Pro (73.7 против 69.2) и на TerminalBench. Подписки $20 / $100 / $200 в месяц; токенный тариф Ultra — $5 за млн входных и $30 за выходные. Пока недоступна в ЕС. Главная идея — топовое качество без привязки к одному поставщику и без риска экспортных запретов. (sakana.ai/fugu)
Recall. Локальная память проекта для Claude Code. Claude каждую сессию начинает с чистого листа — Recall ведёт лог в .recall/history.md и сжимает его в короткую сводку context.md, которую подгружает в следующий запуск. Сжимает не моделью, а алгоритмами TF-IDF и TextRank прямо на машине: ноль платных токенов, ничего не уходит наружу. Команда /recall:save, ставится через /plugin marketplace add raiyanyahya/recall. Бесплатно, MIT. Экономит лимиты дважды: и на построении сводки, и на том, что не надо заново объяснять проект. (GitHub)
Unlimited-OCR. Открытая модель Baidu, которая распознаёт целый многостраничный PDF за один проход, а не постранично. OCR — это перевод картинки документа в текст; здесь модель ещё и держит длинный документ связным на выходе. Два режима для одиночных страниц (Gundam для плотных, Base для обычных), запуск через Transformers или совместимый с OpenAI сервер SGLang. Бесплатно, MIT, вышла сегодня. (Hugging Face)
Poolside Laguna M.1. Открытые веса под Apache 2.0: 226 млрд параметров, контекст 256 тысяч токенов. Ещё одна серьёзная модель с открытыми весами, которую можно запускать у себя. (Hugging Face)
Viktor. Рабочий агент прямо в Slack и Microsoft Teams: строит отчёты и дашборды, пишет код, подключается к 3200+ инструментам. Бесплатно на старте. Удобно тем, кто живёт в корпоративном чате и не хочет отдельного приложения. (viktor.com)
Adapt. Общий «мозг» компании в Slack и вебе: люди и агенты отвечают на вопросы и действуют поверх всех подключённых систем. Дают $100 бесплатных кредитов на пробу. (adapt.com)
Juno. Превращает голосовые заметки на Mac в чистый текст прямо внутри Mail, Slack, Notes и Cursor. Бесплатно, открытый код — для тех, кто думает вслух быстрее, чем печатает. Похожая, но более широкая идея у VoiceOS: диктовка плюс управление рабочим столом голосом, ещё и на Windows. (Juno, VoiceOS)
Windows-Copilot-API — серая зона. Проект превращает встроенный в Windows Copilot в OpenAI-совместимый API: доступ к моделям GPT без ключей и оплаты, через локальный сервер. Любопытно технически и явно нарушает условия Microsoft, так что для боевых задач не годится. Показываем как пример обратной разработки, а не как рекомендацию. (GitHub)
Новости и тренды
Паспорт для Claude. Anthropic выкатила проверку личности: партнёр Persona просит настоящее государственное удостоверение и живое селфи. Пока это не для всех — статья компании туманна и говорит про «отдельные возможности» и «плановые проверки целостности платформы». Anthropic клянётся, что не обучает на ваших документах, не продаёт их и хранит минимум. Но срок хранения, список стран и пороги по нагрузке не названы.
В тот же день разлетелось эссе Эндрю Марбла «уйти на открытые модели почти ничего не стоит». Аналогия: открытые модели в 2026-м — как Linux в 2008-м, уже не жертва. Они отстают от лидеров лишь на месяцы, и вокруг них уже есть хорошие инструменты. Но сам автор признаёт ловушку: чужие хостинги открытых моделей по приватности хуже Anthropic, а свой сервер дорог и медленен. Что это значит: переход на открытые модели — это про свободу и автономию, а не автоматически про приватность; настоящая приватность только в локальном запуске. (Anthropic, эссе)
DeepMind: как держать ИИ-агента в узде. Google DeepMind выпустила «дорожную карту контроля ИИ» — план безопасности для мощных внутренних агентов. Главная мысль: даже обученного быть полезным агента стоит считать потенциальной внутренней угрозой, как сотрудника с доступом к важным системам. Поверх обучения нужны системные защиты: доверенные ИИ-надзиратели следят за рассуждениями и действиями, а контроль масштабируется по риску — от отложенной проверки до блокировки в реальном времени. Метрики прямо из кибербезопасности: охват, доля пойманного и время реакции. Что это значит: та же логика годится и для ваших агентов — мониторинг плюс песочница, а не слепое доверие. (DeepMind)
MonitoringBench: проверяющий не так надёжен, как кажется. Новый бенчмарк из 2644 атак показал: ИИ-надзиратель, который должен ловить вредящего агента, ловит куда хуже, чем выглядит по средним цифрам. Полуавтоматическая доработка атак уронила долю пойманного: у лучшего надзирателя Opus 4.5 — с 94.9% до 60.3%, у GPT-5 — с 60.2% до 19.5%. Сильнее всего проверяльщики проваливаются, когда атакующий не объясняется: Opus сам придумывает атаке невинное оправдание. Способность надзирать сосредоточена в передовых моделях — слабые дают ложное чувство безопасности. Что это значит: не сажайте дешёвую модель сторожить вашего агента. (LessWrong)
ИИ-текст палится одинаковостью. Михал Залевский (lcamtuf) собрал коллаж из ~150 обложек детских книжек «100 000 почему» с Amazon — почти неотличимых: у всех в верхнем углу рычащий динозавр, а «авторы» все по фамилии Bright. Вывод: модели квазидетерминированы и на похожий промпт выдают одинаковый набор приёмов примерно в 80% случаев. Палит не отдельная манера, а то, что сотня «авторов» сходится к одному и тому же. Что это значит: общий промпт без вашей конкретики превращает текст в неотличимый шлак; добавляйте своё, иначе ваш блог можно переименовать в «100 000 почему». (lcamtuf)

ИИ сломал найм. В Harvard Business Review разобрали, как генеративный ИИ обесценил привычные сигналы найма: резюме, сопроводительные и гладкие ответы на интервью теперь подделать бесплатно и в любом масштабе. Авторы изучили 120 рекрутёров и больше 6000 скринингов и зовут перестраивать ранний отбор вокруг живого мышления и рабочих проб, а не статичных корочек. Что это значит: нанимаете — проверяйте суждение вживую; ищете работу — преимущество отполированного ИИ резюме быстро тает. (HBR)
Рабочие и политики против ИИ-гонки. Бунт против ИИ организуется сразу на двух фронтах. Внутри компаний: 1600+ сотрудников Meta подписали петицию против сбора их данных для обучения. Профсоюзы поднялись в DeepMind и Oracle, а с 2025-го с ИИ связывают уже 150 тысяч ИТ-увольнений. В политике: демократические активисты запустили супер-PAC Guardrails Alliance на $5 млн против про-ИИ-машины Leading the Future с её $100+ млн. Что это значит: спор об ИИ перестаёт быть техническим и становится трудовым и предвыборным. (Tech Policy Press, TechCrunch)
Коротко:
- Дин Болл ушёл в OpenAI возглавлять команду Strategic Futures по политике вокруг передового ИИ. (Axios)
- Snap выделил свою генеративную видео-команду в отдельную компанию Dotmo под ИИ для интерактивных игр — внутри держать дорого. (TechCrunch)
- AWS ведёт ранние переговоры продавать свои чипы Trainium в чужие дата-центры; потенциальный оборот оценивают в ~$50 млрд — развитие темы 20 июня. (Bloomberg)
- DeepMind отдельно выпустила исследование о четырёх возможных путях от AGI к сверхинтеллекту. (DeepMind)
- Директор АНБ заявил, что Mythos «вскрыл почти все наши секретные системы за часы» — новый штрих к саге вокруг запрета моделей Anthropic. (Economist)
- Эксперимент Коби Хакенбурга: передовой ИИ почти утроил пожертвования в кампании по сравнению с профессиональными агитаторами — про силу ИИ-убеждения. (пост)